이진 분류의 평가
정확도(accuracy)의 맹점
클래스가 불균형한 데이터에서 모델의 성능과 관련 없이 높은 평가를 줄 수 있다. 현실세계의 데이터는 대부분 불균형한 데이터다. 이런 사례는 Accuracy로 측정하면 99.99 % 가 나온다면 제대로 측정하기가 어렵다.
ex. 제조업에서 양불검출, 스팸메일 분류, 희귀질병(암 진단여부) 검사, 게임 어뷰저 등
ex. 금융 : 은행 대출 사기, 신용카드 사기, 상장폐지종목 여부 등
ex. IT관련 => 게임 어뷰저, 광고 어뷰저, 그외 어뷰저
대회에서 어뷰저 관련 내용을 찾을 때는 Fraud 등으로 검색하면 여러 사례를 찾을 수 있다.
Confusion Matrix
1종 오류
통계상 실제로는 음성인데 양성으로 결과가 나오는 것을 말한다. Precision(정밀도)을 측정지표로 사용한다.
ex. 스팸 메일, 유무죄 선고, 중고차 성능 판별 등으로
2종 오류
통계상 실제로는 양성인데 음성으로 결과가 나오는 것을 말한다. Recall을 측정지표로 사용한다.
ex. 암인데 암이 아니라고 예측, 지진이 났는데 대피방송을 하지 않음 , 자율주행의 인식 X 등
ex. "테슬라 자율주행, 어린이 보행자 인식 못해"…서있는 마네킹 '쾅'
Precision(정밀도) : 예측값이 Positive인 것 중 TP의 비율
- tp / (tp + fp)
Recall(재현율) : 실제값이 Positive인 것 중 TP의 비율
- tp / (tp + fn)
f1 score : Precision과 Recall의 조화평균
Precision과 Recall은 trade-off 관계
ROC와 AUC
공돌이의 수학정리노트
기존에는 예측을 할 때 주로 predict 를 사용했지만 predict_proba 를 하게 되면 0,1 등의 클래스 값이 아닌 확률값으로 반환합니다.
임계값을 직접 정해서 True, False를 결정하게 되는데 보통 0.5 로 하기도 하고 0.3, 0.7 등으로 정하기도 합니다.
임계값 == Threshold
0804 실습
코랩에서 구글드라이브 연결하기
코드 스니펫을 이용하면 편하다! 좌측 하단의 <>를 입력하여 'mount'를 검색하자!
Resampling - 참고링크
현실 속 데이터는 불균형한 데이터가 매우 많다. 1년 중 눈이 오는 날이라던가, 지진이 나는 날이라던가, 양불 검사등을 생각해볼 수 있다. 현실의 데이터는 5:5의 비율을 맟추기 힘들기에 우리는 resampling을 한다.
Resampling은 Undersampling과 Oversampling이 있다.
Under-Sampling 과 Over-Sampling
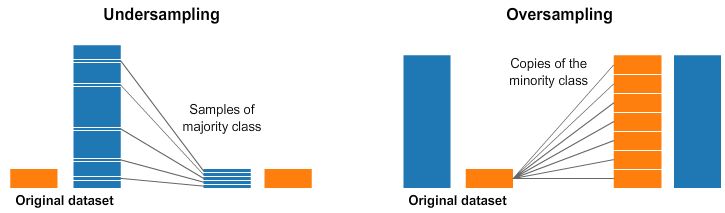
Under-Sampling
크기가 작은 데이터 값을 기준으로 데이터의 개수를 맞춘다.
- ex. 0이 28만여개, 1이 492로 분류하는 데이터에서 0을 492개만 추출하여 데이터의 개수를 줄인다
데이터의 소실이 굉장히 크다는 단점이 있다.
sample을 이용해 손쉽게 맞출 수 있다.

Over-Sampling*
크기가 큰 데이터 값을 기준으로 데이터의 개수를 맟춘다.
- ex. 0이 28만여개, 1이 492로 분류하는 데이터에서 0을 492개만 추출하여 데이터의 개수를 줄인다
데이터의 소실이 없으나 오버피팅의 우려가 있다.

SMOTE
- Synthetic Minority Over-sampling Technique의 약자로 합성 소수자 오버샘플링 기법
- 적은 값을 늘릴 때, k-근접 이웃의 값을 이용하여 합성된 새로운 값을 추가
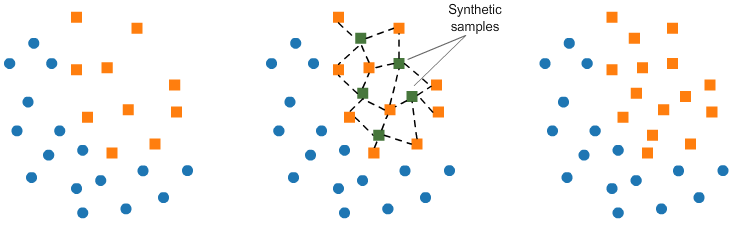
알고리즘 컨셉
1) 소수 클래스 데이터 중 무작위로 한 점을 선택 (A)
2) 이 점에서 가장 가까운 k개의 소수 클래스 데이터를 탐색
3) 이 중 하나를 무작위로 선택 (B)
4) 두 데이터 (A와 B)를 잇는 선을 긋고
5) 그 선분 위의 임의의 점을 선택하여 합성 데이터 (C) 생성
6) 원하는 만큼의 데이터가 생성될 때까지 반복
딥러닝
머신러닝과 비교했을 때, 비정형 데이터를 다루는 데 딥러닝이 더 유리하다.
딥러닝에는 데이터 전처리 기능이 포함되어 있다. 피처를 추출할 때, 이미지를 넣어주면 알아서 해준다.
인공지능의 역사
- 초기의 인공 신경망은 XOR 문제를 해결할 수 없었다. => 다층 구조를 통해 해결
활성화 함수
Sigmoid, tanh
=> 기울기 소실 문제 발생 : 역전파 과정에서 입력층으로 갈수록 기울기가 0으로 수렴하게 됨
=> ReLU, Leaky ReLU를 사용하여 기울기 소실 문제를 해결!
'멋쟁이사자처럼 AIS7 > 오늘코드' 카테고리의 다른 글
| [1130] DNN (0) | 2022.11.30 |
|---|---|
| [1129] 인공신경망과 텐서플로 (0) | 2022.11.29 |
| [1123] 부스팅 3대장과 분류의 평가지표 (0) | 2022.11.23 |
| [1116] Boosting Model (0) | 2022.11.16 |
| [1115] Feature Engineering(3) - Benz (0) | 2022.11.15 |

댓글