본 내용은 K-MOOC 실습으로 배우는 머신러닝 강의의 내용을 듣고 작성하였습니다.
실습으로 배우는 머신러닝
www.kmooc.kr
1. Introduction to Machine Leaning
AI, ML, DL
결국에 머신러닝이라는 것은 함수를 학습하는 것이다. 데이터가 있고 컴퓨터를 학습시킬 수 있는 알고리즘을 컴퓨터에게 입력을 시켜주면 컴퓨터가 스스로 데이터 안에 있는 유용한 패턴을 찾아서 이와 같이 함수를 찾아준다. 그러면 실제 상황에서는 학습된 함수를 가져와서 유용한 output을 내는 함수로서 사용을 한다.
과거의 AI, Traditional AI는 Knowledge Engineering라고 불렸다.이 단어가 암시하는 바와 같이 지식을 공학, 지식을 잘 조직해서 우리가 유용한 함수로 만드는 것이다. 과거에는 데이터가 있고 앞에서 얘기했던 머신러닝에서 학습한다는 그 유용한 함수를 사람이 했다. 직접 디자인을 해서 일련의 로직들, 일련의 절차들을 모두 다 사람의 지식을 그대로 모사하게끔 만들었고, 그 다음에 그거를 컴퓨터에게 입력을 시켜서 최종적인 output을 내게끔 그렇게 디자인이 되어 있었다. 이게 과거의 AI 트렌드였다.
최근에 각광받고 있는 딥러닝, 머신러닝과 이러한 개념의 차이는 데이터를 입력해주고그 다음에 function의 기본적인 형태를 컴퓨터에게 알려주면 트레이닝 과정을 통해서 최종적인 optimal function, 굉장히 좋은 유용한 함수를 컴퓨터 스스로 학습한다는 점이다. 컴퓨터 스스로 학습을 하고 학습된 데이터를 현실로 가져와 사용한다.
GPU
그럼 어떻게 머신러닝이 가능해졌는가? 많은 데이터를 처리하고 계산할 수 있도록 분산화된 컴퓨팅 기술이 등장했기 때문이다. GPU라는 효율적이고 빠른 장비의 등장은 머신러닝과 딥러닝의 발전을 대두시켰다.

GPU란 Graphics Processing Unit의 약자로 일반적으로 그래픽 카드를 의미한다. 딥러닝 알고리즘은 본질적으로 많은 단순 사칙연산(행렬 곱셈 등)을 수행하게 되는데, 이 연산은 병렬화가 아주 쉽기에 GPU를 통해 한번에 연산이 가능하다. CPU는 단순 사칙 연산을 담당할 수 있는 산술논리연산(ALU) 장치가 1개이므로 복잡한 단일계산에서는 GPU보다는 유리하지만, 병렬 작업에서 불리하여 GPU보다 성능이 떨어지기에 딥러닝 학습에 유용하게 사용된다.
- 기본적인 컴퓨터 환경 : CPU, 60 ~ 80 개의 코어
- 최근 : GPU 를 이용한 빠른 연산(분산 처리) , 10000 ~ 20000개의 코어
ML
Machine learning is the study of computer algorithms that allow computer programs to automatically imporve through experience(Mitchell, 1997)
4가지 구성 요소
- 환경(Environment) : 머신러닝 알고리즘이 적용되는 환경, 경험(데이터)을 제공해줌
- 데이터(Data) : 환경과 상호작용하면서 기억해야할 활동의 저장 결과
- 모델(Model) : 함수
- 퍼포먼스(Performance) : 모델의 성능 평가의 기준, 측정 단위
머신러닝의 궁극적인 목적은 입력값과 출력값의 상관관계를 아는 것으로, 이 둘을 이어주는 적절한 함수를 찾는 것이다.
우리는 현실과 예측의 오차가 작은 적절한 함수를 학습해야 한다
머신러닝의 학습?
1) 모형을 세우고 2) 손실함수를 정의하고 3) 최적화
- 모형의 대략적인 형태를 알려줘야 함
ex. input과 output은 선형적인 관계, input X β = output - 손실함수의 정의
손실함수의 최솟값 => 미분해서 0되는 값 찾기
완벽하게 training error 가 0이 되는 간 사실상 예측X - 최적화: 최적의 결과를 도출해내도록 학습
Linear Regression

- 인풋과 아웃풋이 선형적
- y^은 추정값, y는 실재값
✅ hyperparmeter를 조절하여 model complexity를 결정할 수 있다. 이는 모델의 과적합 여부에 영향을 끼친다.
2. Machine Leaning Pipeline
1) 인공지능과 머신러닝 개요
Data Science Process

1) Prior Knowledge = Business Understanding + Data Understanding
2) Preparation = Prepare Data
3) Modeling = Training Data ➡️ Building Model Using Algorithms(function)
4) Application = Test data ➡️ Applying Model and performance evaluation
---------------------------------------------------------------------------------------------------- 여기까지 배움
5) Deployment(배포)
6) Knowledge and Actions
Data 관련 용어
Dataset,
Data Point(Observation, 관측치),
Feature(Variable, Attribute, X, 입력변수),
Label(Target, Response, y, 출력변수)
✅ 정형 데이터와 비정형 데이터
정형데이터는 테이블 형태로 나타낼 수 있는 데이터를 의미한다. 비정형 데이터는 이미지, 텍스트, 음성 등과 같이 테이블 형태로 표현하기 어려운 데이터를 의미한다.
분류와 회귀
범주형인 종속 변수를 예측하는 데 사용하는 모델을 분류라 하고, 연속형일 때 사용하는 모델을 회귀라 한다.
Data 준비 과정
Dataset Exploration(EDA)
Missing Value(결측치)
Data Types and Conversion(숫자 벡터 값으로!)
Normalization(정규화, 단위를 맞춰줌)
Outliers
Feature Selection
Data Sampling
Modeling

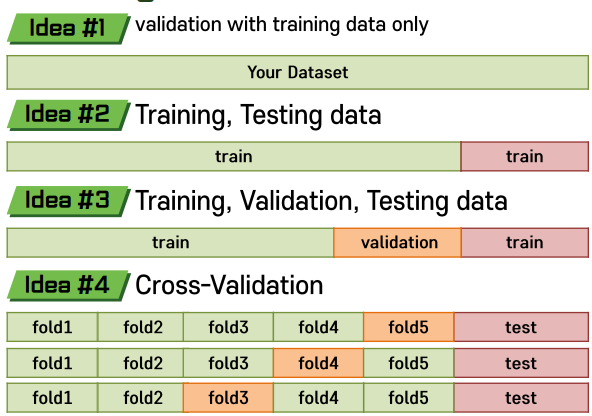
Modeling 검증

모델이 지나치게 자세하게 학습될 경우 Overfitting의 우려가 있고, 너무 적게 학습될 경우 Underfitting의 우려가 있다. 하이퍼 파라미터를 튜닝하여 모델의 복잡도를 조절할 수 있는데 흔히 모델이 복잡하면 과대적합, 단순하면 과소적합의 우려가 있다고 한다.





댓글